
Solveur de Scrabble
Menu principalNé d’un pari un peu fou avec Gnieark, ce solveur de Scrabble est écrit entièrement en Bash.
Par solveur de Scrabble, j'entends un programme qui, étant données une liste de lettres (avec ou sans lettres blanches), va retourner la liste de tous les mots possibles. Il n'est donc pas question ici de reproduire un plateau de Scrabble ou de présenter un calcul des points en fonction des lettres.
Ce billet a pour but d'expliquer le fonctionnement de ce programme.
Téléchargement
Télécharger scrabblesolver.tar.xz Taille du fichier : 1,5 Mo
Pré-requis
Ce programme nécessite l'utilitaire dialog. Il est possible de l'installer sous Debian via la commande :
sudo apt install dialogHormis cette contrainte, il utilise également les outils grep, sed, tr et cut. S'agissant d'outils standard, il sont généralement déjà installés sur votre machine (si c'est un GNU Linux bien sûr).
Dernier point : s'agissant d'un script Bash, celui-ci ne fonctionnera pas si vous cherchez à l'exécuter en tapant sh scrabblesolver.
Copies d’écran
Les 2 copies d'écrans suivantes présentent la saisie des lettres et l'affichage des resultats.
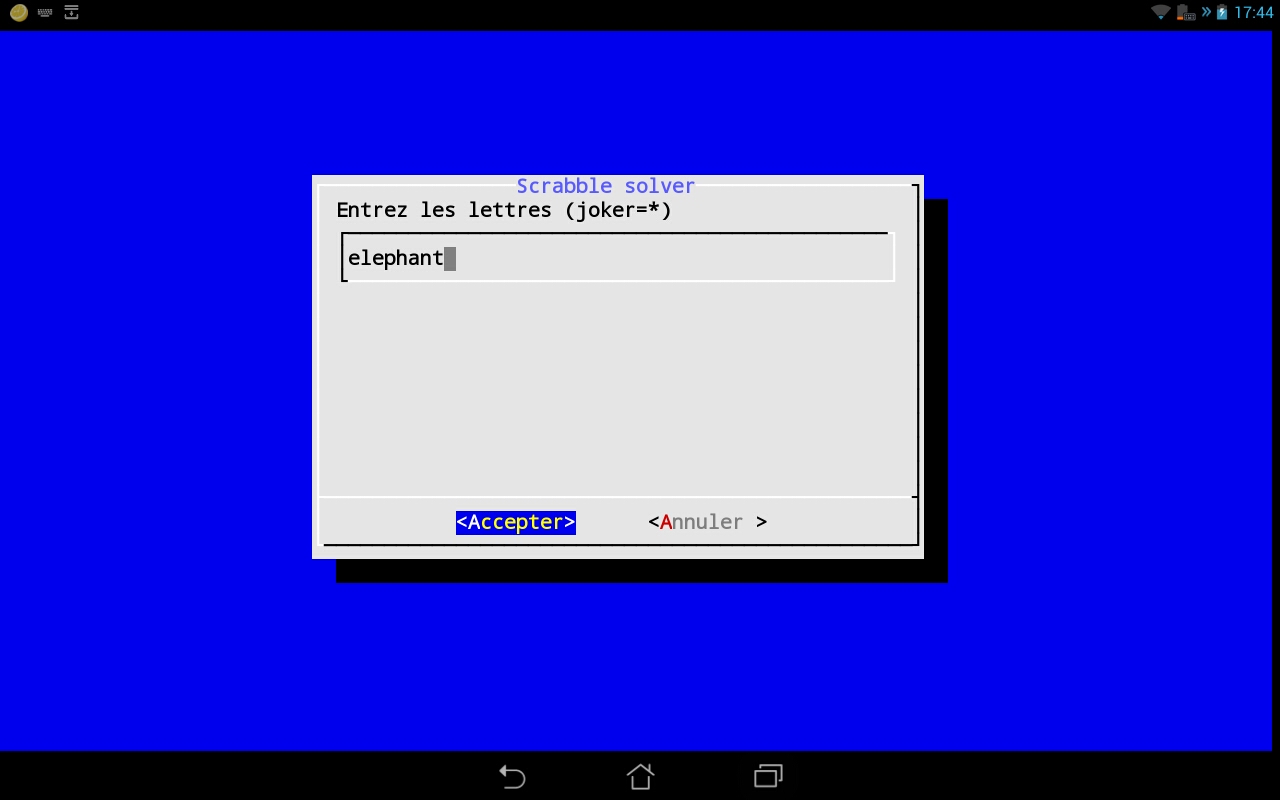
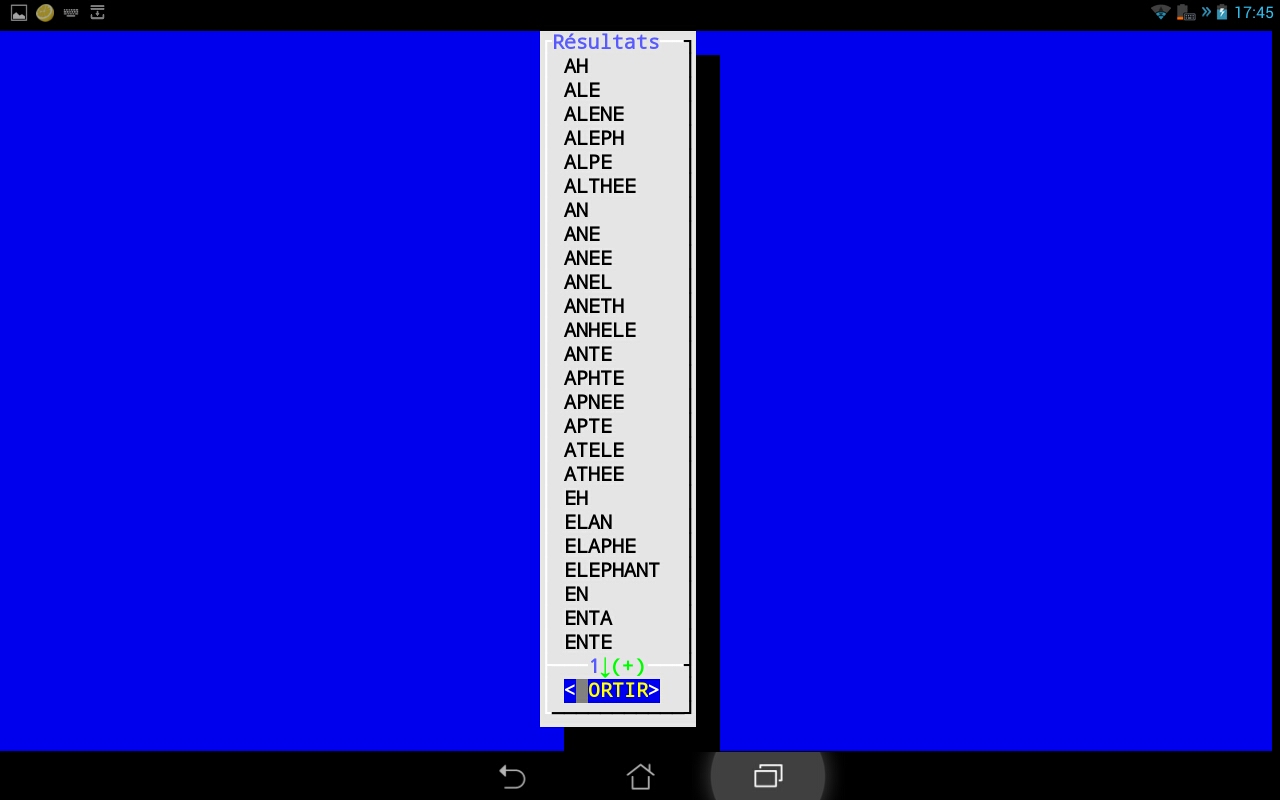
Préparation du fichier ODS6.txt
Pour disposer de temps de réponse très bas de la part d'un script Bash, il faut se reposer sur un nombre de processus réduit et des utilitaires performants. Dans le cas présent, tout le travail de recherche est confié à l'utilitaire egrep. Il faudra donc lui donner la chaîne de recherche correspondant aux lettres fournies par l'utilisateur et préparer le fichier ODS6.txt.
Ce fichier contient la liste de tous les mots possibles et autorisés au Scrabble français :
- les mots français,
- sans aucun nom propre,
- sans accent,
- d'un minimum de 2 lettres,
- d'un maximum de 15 lettres (le Scrabble se joue sur une grille de 15×15),
- en majuscules.
Afin de faciliter et optimiser la recherche, le script utilisera des séquences de lettres dans l'ordre alphabétique. Par exemple, ELEPHANT sera traité sous la forme AEEHLNPT. Le script Bash suivant permet de générer la liste préparée :
cat ODS6.txt | while read ligne
do
printf '%s' "$ligne" | sed 's/\(.\)/\1\n/g' | sort | tr -d '\n'
echo
doneLa lignecat ODS6.txt | while read ligne lit le fichier ODS6.txt ligne par ligne dans la variable ligne.
La ligneprintf '%s' "$ligne" | sed 's/\(.\)/\1\n/g' | sort | tr -d '\n' réalise les opérations suivantes :
La ligneprintf '%s' "$ligne" | sed 's/\(.\)/\1\n/g' | sort | tr -d '\n' réalise les opérations suivantes :
- envoi de la ligne à
sed, -
sedajoute un retour chariot après chaque caractère et envoie le résultat àsort, -
sorttrie les lignes de 1 caractère produites parsedet les envoie àtr, -
trsupprime tous les retour chariots et affiche le résultat.
La ligne echo insère un retour chariot.
Ainsi la chaîne ELEPHANT subit le traitement suivant (\n doit être compris comme un retour chariot et non comme deux caractères) :
-
sed: ELEPHANT -> E\nL\nE\nP\nH\nA\nN\nT\n -
sort: E\nL\nE\nP\nH\nA\nN\nT\n -> \nA\nE\nE\nH\nL\nN\nP\nT -
tr: \nA\nE\nE\nH\nL\nN\nP\nT -> AEEHLNPT
Ce n'est malheureusement pas suffisant pour notre solveur. Si cette forme permet de retrouver rapidement les mots contenants certaines lettres, elle ne permet pas de retrouver le mot lui-même ! Pour cela, il faut fusionner la liste originale et la liste préparée. À ce titre la commandepaste se révèle particulièrement utile. Par exemple :
paste -d '=' file1 file2Sifile1 contient les lignes :
A
B
CEtfile2 les lignes :
1
2
3L'exemple produira la sortie suivante :
A=1
B=2
C=3Cela nous permet de créer le fichier ODS6.prep.txt qui contiendra des lignes de la forme :
AEEHLNPT=ELEPHANTLe fichierODS6.prep.txt ainsi produit est directement utilisable par le scriptscrabblesolver.
Explications du script
La fonction addchar
La fonctionaddchar prend une chaîne de caractère et ajoute un caractère après chaque caractère de cette chaîne.
Exemple
addchar "abc" "=" # Retourne la chaîne "a=b=c="Cette opération est utile dans le cadre de ce programme car sa principale activité va être de constituer une chaîne de caractère à destination de la commandegrep.
Elle pourrait être écrite avec une commandesed mais elle fait partie du processus d'optimisation.
La boucle principale parcourt la chaîne caractère après caractère. Pour chaque caractère rencontré, elle affiche le caractère lu concaténé au caractère passé en paramètre. La boucle repose complètement sur des fonctionnalités de Bash.
La bouclefor fait varier $i de 0 au nombre de caractères de la chaîne(${#string}). Pour extraire le caractère de la chaîne, elle utilise la construction${string:start:length} qui exrait une sous-chaîne d'une chaîne de caractères. Voici la boucle :
for ((i=0; i<${#string}; i++))
do
printf '%s' "${string:$i:1}$char"
done